
Verify if specific content on your webpage is SEO friendly & is being picked by Googlebot during indexing.
What it means?
You generally expect Googlebot to index all the content on your page. But, the bot may not always index your page's dynamic content. This is the content that requires user-action (such as scrolling) or JavaScript execution to appear on your page. With access to Google Search Console (or Google Webmaster) for the concerned site, you can use the tools there to check if the content you expect Googlebot to index is being indexed. And in case you don't have Google Search Console access, there still are ways to do so.
[Google Search Console] Check if certain content appeared in the crawled copy of your page:
Use this method if the page in question is already live & has already been indexed by Google & if you have access to Google Search Console for the site. Login to Google Search Console and enter the URL you want to verify to access Google's crawled copy of your page:
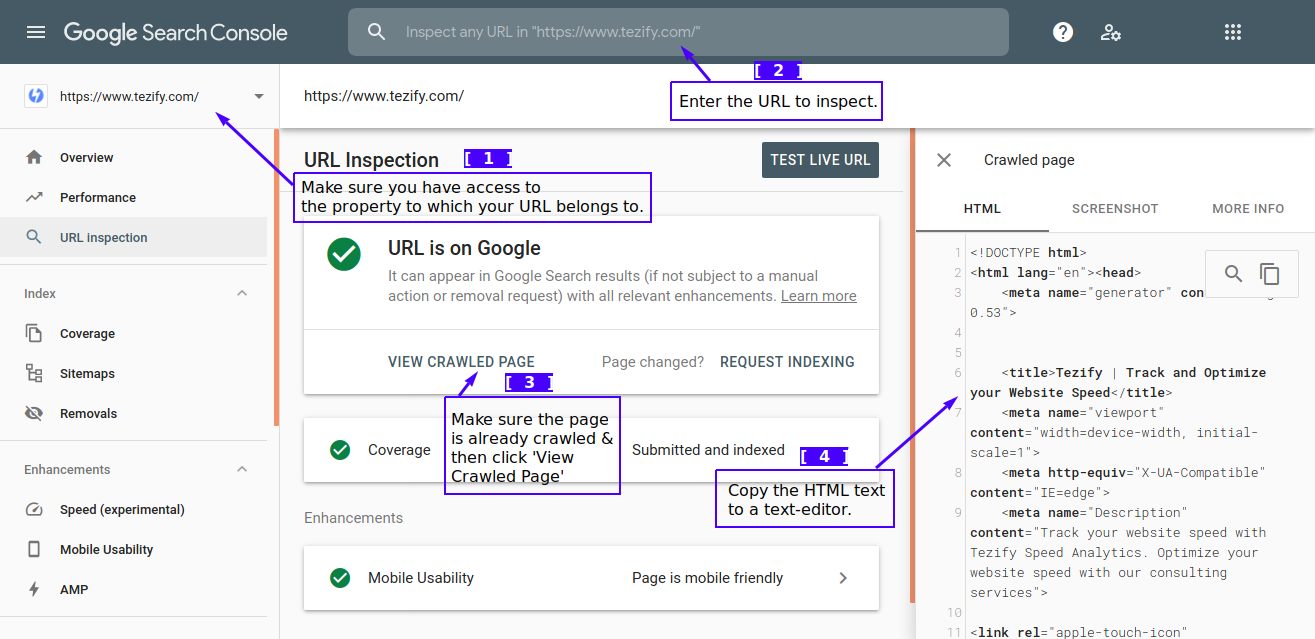
Once you copy the HTML source of the crawled page, simply search for your desired content within the HTML source:
If the content doesn't appear as explained above, Googlebot *may* not be indexing that content.
[Google Search Console] Check if Googlebot will index certain content in next crawl:
If you seek to check a certain page / content of the page that isn't yet indexed by Googlebot, you can vertify using 'Test Live URL' feature of Google Search Console:
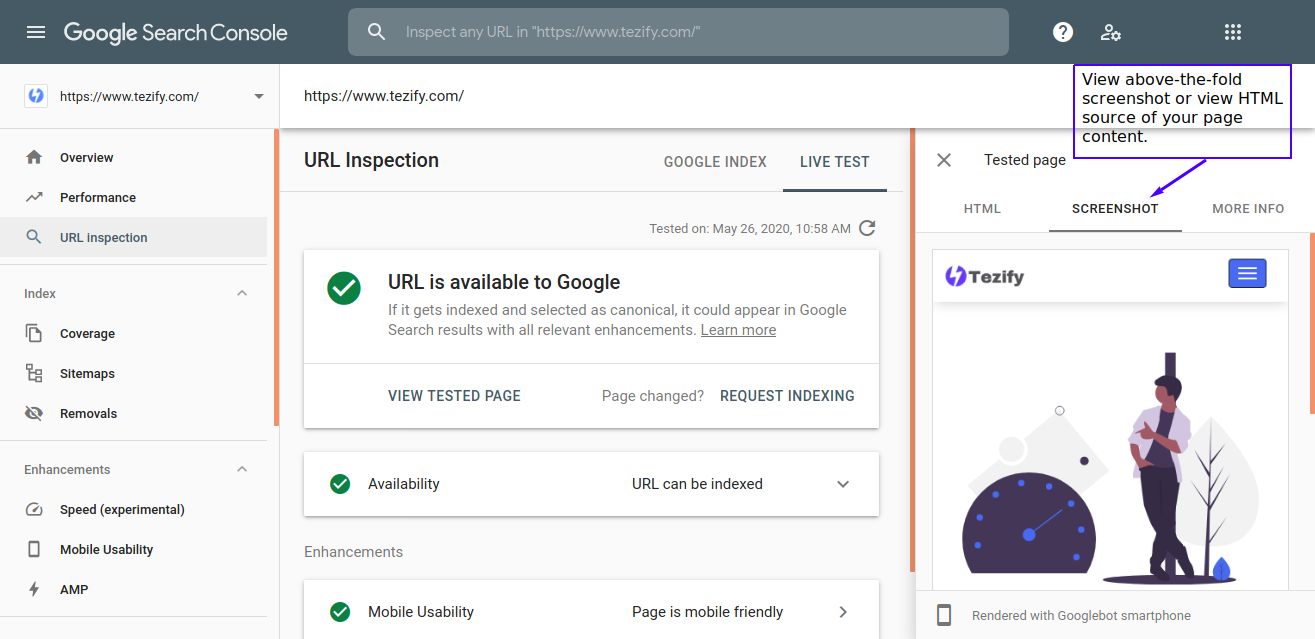
For above-the-fold content, you can view how the content renders and for rest of the page, you can copy the HTML source of the page and search for your desired content within the HTML source.
[Without Google Search Console] Check if Google has indexed specific content on your live page:
The most elegant & sure-shot way to verify if Google is indexing a specific text from your live page is to search for that text on Google with `site:
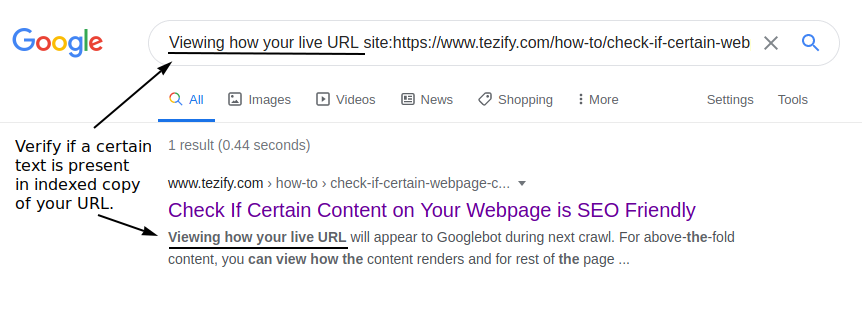
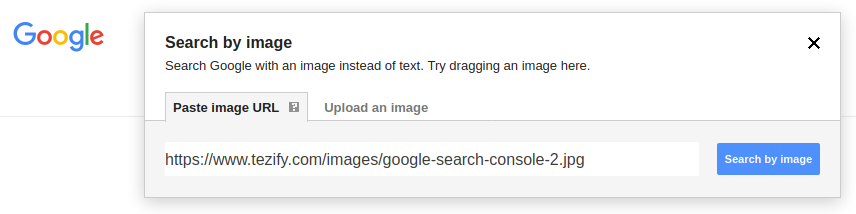
To perform a similar verification for images, use Google's reverse image search:
If Google doesn't show the searched content as expected, try the approach detailed in the next section.
[Without Google Search Console] Check if Googlebot will index certain content in next crawl:
This is a powerful method because it works even if:
However, it requires accessing certain tech-tools to execute. First-up, keep the below user-agent strings handy:
Here's the User-Agent string for mobile:
Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.0.0 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)And here's one for desktop:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Googlebot/2.1; +http://www.google.com/bot.html) Chrome/74.0.0.0 Safari/537.36Now, our goal is to get the same HTML for our URL that Googlebot will be provided. We can do so via:
Below is the curl command you can run (simply replace your URL) to obtain the HTML.
curl '<ENTER_YOUR_URL_HERE>' \
-H 'cache-control: no-cache' \
-H 'user-agent: Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.0.1 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)' \
-H 'accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9' \
-H 'accept-language: en-GB,en-US;q=0.9,en;q=0.8' \curl '<ENTER_YOUR_URL_HERE>' \
-H 'cache-control: no-cache' \
-H 'user-agent: Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; Googlebot/2.1; +http://www.google.com/bot.html) Chrome/74.0.0.1 Safari/537.36' \
-H 'accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9' \
-H 'accept-language: en-GB,en-US;q=0.9,en;q=0.8' \Once you obtain the HTML response from any of the above methods, you can search for the specific content within the HTML. If present as a regular HTML content / tag, it shall be picked by Googlebot during next crawl. If it requires execution of JavaScript, it *may* or *may not* be picked by the Googlebot during the next crawl immediately.